
Проверка исправности работы диска в Ubuntu
Как проверить целостность носителя данных (жесткий диск или флэш-диск)? Ubuntu Linux
Во всем этом ответе я предполагаю, что диск хранения отображается как блок-устройство на пути /dev/sdc . Чтобы найти путь к накопителю в нашей текущей настройке, используйте:
- Гном-диски (ранее Gnome Disk Utility, aka palimpsest ), если имеется GUI, или
- на терминале посмотрите вывод lsblk и ls -l /dev/disk/by-id и попробуйте найти подходящее устройство по размеру, разбиению на разделы, производителю и имени модели.
Базовая проверка
- обнаруживает полностью невосприимчивые носители
- почти мгновенно (если среда не сплющена или не сломана)
- безопасно
- работает на носителях только для чтения (например, CD, DVD, BluRay)
Иногда среда хранения просто отказывается работать вообще. Он по-прежнему отображается как блок-устройство для ядра и диспетчера дисков, но его первый сектор, содержащий таблицу разделов, не читается. Это легко проверить с помощью:
sudo dd if=/dev/sdc of=/dev/null count=1
Если в этой команде появляется сообщение о «ошибке ввода / вывода», наш диск поврежден или иным образом не взаимодействует с ядром Linux, как ожидалось.
В первом случае, немного удачлив, специалист по восстановлению данных с надлежащим образом оборудованной лабораторией может спасти свой контент. В последнем случае стоит попробовать другую операционную систему.
(Я сталкивался с USB-накопителями, которые работают на Windows без специальных драйверов, но не на Linux или OS X.)
Самотестирование SMART
- регулируемая тщательность
- мгновенно замедляться или замедляться (зависит от тщательности теста)
- безопасно
- предупреждает о возможном провале в ближайшем будущем
Устройства, которые его поддерживают, могут быть запрошены о своем здоровье через SMART или проинструктированы о выполнении самотестирования целостности различной тщательности. Это, как правило, лучший вариант, но обычно он доступен только на (не древних) жестких дисках и твердотельных дисках. Большинство съемных флеш-носителей не поддерживают его.
Дополнительные ресурсы и инструкции:
- Ответьте на SMART по этому вопросу
- Как проверить состояние SMART диска на Ubuntu с 14.04 по 16.10?
Проверка только для чтения
- только обнаруживает некоторые ошибки флэш-памяти
- достаточно надежный для жестких дисков
- медленный
- безопасно
- работает на носителях только для чтения (например, CD, DVD, BluRay)
Чтобы проверить целостность чтения всего устройства без его записи, мы можем использовать badblocks(8) следующим образом:
sudo badblocks -b 4096 -c 4096 -s /dev/sdc
Эта операция может занять много времени, особенно если накопитель на самом деле поврежден. Если число ошибок возрастает выше нуля, мы будем знать, что есть плохой блок. Мы можем спокойно прекратить операцию в любой момент (даже сильно, как во время сбоя питания), если нас не интересует точная сумма (и, возможно, место) плохих блоков. При ошибке -e 1 можно автоматически отключить ошибку.
Примечание для расширенного использования: если мы хотим повторно использовать вывод для e2fsck , нам необходимо установить размер блока ( -b ) в том, что содержится в файловой системе. Мы также можем настроить количество данных ( -c , в блоках), протестированных одновременно, для повышения пропускной способности; 16 MiB должно быть хорошо для большинства устройств.
Неразрушающий контроль чтения и записи
- очень тщательный
- медленный
- совершенно безопасный (запрет сбоя питания или прерывистая яровая паника)
Иногда – особенно с флэш-носителями – ошибка возникает только при попытке записи. (Это не будет надежно обнаруживать (flash) носители, которые рекламируют больший размер, чем они есть на самом деле, вместо этого используйте Fight Flash Fraud .)
- НИКОГДА не используйте это на жестком диске с установленными файловыми системами ! badblocks отказывается работать на них в любом случае, если вы не навязываете это.
- Не прерывайте эту операцию! Ctrl + C (SIGINT / SIGTERM) и ожидание изящного преждевременного завершения – это нормально, но killall -9 badblocks (SIGKILL) – нет. При сильном завершении badblocks не может восстановить исходное содержимое тестируемого диапазона блоков и оставить его перезаписанным с помощью мусорных данных и, возможно, испортить файловую систему.
Чтобы использовать неразрушающие проверки чтения и записи, добавьте параметр -n в badblocks выше команду badblocks .
Деструктивная проверка чтения и записи
- очень тщательный
- помедленнее
- УДАЛЯЕТ ВСЕ ДАННЫЕ НА ДИСКЕ
Как и выше, но без восстановления предыдущего содержимого диска после выполнения теста записи, он немного быстрее. Так как данные все равно стираются, принудительное прекращение остается без (дополнительного) отрицательного результата.
Чтобы использовать деструктивные проверки чтения и записи, добавьте параметр -w к указанной команде badblocks .
IMO smartctl является лучшим инструментом.
Вероятно, вам придется сначала установить его
sudo apt-get install smartmontools
затем
sudo smartctl -a /dev/sda | less
для печати данных, атрибутов и доступных результатов тестирования. Чтобы уйти меньше, введите q . альтернативно
sudo smartctl -H /dev/sda
просто распечатать данные о здоровье.
Чтобы начать новый короткий (несколько минут) или длительный (до многих часов) самотестирование в фоновом режиме:
sudo smartctl -t [short|long]
GSsmartControl и Гном-диски если вы предпочитаете графические интерфейсы.
http://gsmartcontrol.sourceforge.net/
Смотрите такжеhttps://help.ubuntu.com/community/Smartmontools
http://www.cyberciti.biz/tips/linux-find-out-if-harddisk-failing.html
http://www.techrepublic.com/blog/linux-and-open-source/using-smartctl-to-get-smart-status-information-on-your-hard-drives/
F3 (Fight Flash Fraud) – еще один вариант, который должен дополнительно обнаруживать фальшивые флеш-накопители (флеш-накопители, чья фактическая емкость составляет часть объявленной емкости):
- Вставьте диск
Установить F3
sudo apt-get install f3
Запись тестовых данных на свободное место на диске
f3write /media/$USER/D871-DD7C/
Прочтите данные теста
f3read /media/$USER/D871-DD7C/
Badblocks работает хорошо, но не предназначен для обнаружения фальшивых флеш-накопителей и может не сообщать о каких-либо ошибках .
Вы можете протестировать-прочитать весь диск, показывая индикатор прогресса:
time sudo pv /dev/sdc >/dev/null
Некоторые проблемы с диском проявляются в сообщениях об ошибках ввода-вывода.
Это немного лучше, чем dd из-за индикатора прогресса, и потому, что интерфейс командной строки является немного более стандартным и немного менее типичным .
Обратите внимание, что pv – это в основном и улучшенная версия cat . Он не может быть установлен по умолчанию, но может быть установлен с помощью sudo apt-get install pv .
Аналогичный подход состоит в том, чтобы прочитать диск с одним из нескольких доступных инструментов, которые специально знают об ошибках ввода-вывода диска, и имеют функцию «трудно усваивать данные». Найдите ddrescue в диспетчере пакетов.
Проверка диска в консоли Linux | сЭВО:эволюция работ
Проверка диска на наличие плохих секторов возникает нежданно и лучше знать как это сделать имея под рукой всё необходимое. Вариантов проверки дисков множество. Расскажу о проверке средствами консоли Linux. Просто и ничего лишнего.
Причины для проверки диска
Основная причина проверки это как правило медленная работа системы или зависание при определенных действиях. Вывести диск из строя могут разные факторы. Вот некоторые из них:
- Время жизни диска не вечна;
- Некорректные выключения системы при пропадании питания;
- Физические удары;
- Запуск холодного диска зимой.
Самое лучшее это периодически проверять диск просто так. На ранней стадии обнаружения гораздо больше шансов сохранить важные данные.
Храните важные данные в двух совершенно разных физически местах. Только такой подход гарантирует вам полную сохранность данных.
Определение диска для проверки
Для того чтобы понять какой диск проверять нам достаточно ввести команду в консоли которая выдаст нам список всех имеющихся дисков в системе.
fdisk -l = вывод части команды = Диск /dev/sda: 232.9 GiB, 250059350016 байт, 488397168 секторов Единицы: секторов по 1 * 512 = 512 байт Размер сектора (логический/физический): 512 байт / 512 байт Размер I/O (минимальный/оптимальный): 512 байт / 512 байт Тип метки диска: dos Идентификатор диска: 0x42ef42ef Устр-во Загрузочный начало Конец Секторы Размер Идентификатор Тип /dev/sda1 * 2048 184322047 184320000 87.9G 7 HPFS/NTFS/exFAT /dev/sda2 184322048 488394751 304072704 145G 7 HPFS/NTFS/exFAT
Мы видим в выводе диск который нам надо проверить. Диск имеет 2 раздела с данными.
Проверка диска на битые секторы
Перед проверкой разделы необходимо отмантировать. Как правило я загружаю операционную систему на базе Linux c Live образа или использую подготовленный PXE сервер на котором присутствуют и другие программы для проверки жестких дисков.
https://www.youtube.com/watch?v=3cFJzkmGh-Q
Можно сразу запустить проверку с исправлением, но мне кажется это не правильно. Гораздо логичней вначале проверить диск и собрать информацию обо всех битых секторах и только после этого принять решение о дальнейшей судьбе диска.
При появлении хотя бы нескольких плохих секторов я больше диск не использую. Пометку плохих секторов с попыткой забрать из них информацию использую только для того чтобы сохранить данные на другой диск.
Создание файла для записи плохих секторов
Создадим файл указав для удобства имя проверяемого раздела.
touch «/root/bad-sda1.list»
Проверка диска утилитой badblocks
Запустим проверку с информацией о ходе процесса с подробным выводом. Чем больше диск тем дольше проверка!
badblocks -sv /dev/sda1 > /root/bad-sda1.list = Информация о ходе процесса = badblocks -sv /dev/sda1 > /root/bad-sda1.list Checking blocks 0 to 976761542 Checking for bad blocks (read-only test): 0.91% done, 1:43 elapsed. (0/0/0 errors) = Подробный вывод результата = badblocks -sv /dev/sda1 > /root/bad-sda1.list Checking blocks 0 to 156289862 Checking for bad blocks (read-only test): done Pass completed, 8 bad blocks found. (8/0/0 errors)
В нашем случае диск с 8 плохими секторами.
Пометка плохих секторов диска
Запустим утилиту e2fsck, указав ей список битых секторов. Программа пометит плохие сектора и попытается восстановить данные.
Указывать формат файловой системы нет надобности. Утилита сделает всё сама.
e2fsck -l /root/bad-sda1.list /dev/sda1 = Вывод команды = e2fsck -l /root/bad-sda1.list /dev/sda1e2fsck 1.43.3 (04-Sep-2016) Bad block 44661688 range; ignored. Bad block 44661689 range; ignored. Bad block 44661690 range; ignored. Bad block 44911919 range; ignored. Bad block 44958212 range; ignored. Bad block 44958213 range; ignored. Bad block 44958214 range; ignored. Bad block 44958215 range; ignored. /dev/sda1: Updating bad block inode. Pass 1: Checking inodes, blocks, and sizes Pass 2: Checking directory structure Pass 3: Checking directory connectivity Pass 4: Checking reference counts Pass 5: Checking group summary information /dev/sda1: ***** FILE SYSTEM WAS MODIFIED ***** /dev/sda1: 11/9773056 files (0.0% non-contiguous), 891013/39072465 blocks
Подготовка диска для проверки
Бывают случаи когда таблица разделов повреждена на диске и нет возможности посмотреть какие есть разделы с данными. Возможно вам не надо никаких данных на диске и вы хотите диск отформатировать и затем проверить. Случаи бывают разные и надо подходить исходя из ситуации.
С помощью команды с ключом -z вы сможете создать заново таблицу разделов и создать необходимые вам разделы.
cfdisk -z /dev/sda Как работать с утилитой cfdisk я не буду, так как это выходит за рамки данной статьи.
Предположим что вы создали из всего диска лишь один раздел /dev/sda1. Для форматирования его в ext4 достаточно выполнить команду:
mkfs.ext4 /dev/sda1 = Вывод команды = mke2fs 1.43.3 (04-Sep-2016)Creating filesystem with 244190385 4k blocks and 61054976 inodesFilesystem UUID: c4a1eeed-960a-4aea-a5ff-02ce93bf0a2eSuperblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208, 4096000, 7962624, 11239424, 20480000, 23887872, 71663616, 78675968, 102400000, 214990848 Allocating group tables: done Writing inode tables: done Creating journal (262144 blocks): doneWriting superblocks and filesystem accounting information: done
Вывод
Проще и понятней механизма проверки диска на битые сектора как в системе Linux я не встречал. Ничего лишнего только суть. Выбор варианта как проверять и когда всегда за вами. После того как я один раз потерял важные данные храню всё важное в 3 разных местах.
, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Проверка исправности работы диска в Ubuntu
Неисправный жёсткий диск — одно из самых неприятных явлений в работе компьютера. Мало того что мы легко можем потерять очень много важной информации и файлов, так и замена HDD неслабо бьёт по бюджету.
Прибавим к этому потраченное время и нервы, которые, как известно, не восстанавливаются. Чтобы не дать проблеме застать нас врасплох и заранее диагностировать её, стоит знать, как проверить жёсткий диск на ошибки в ОС Ubuntu.
Программных средств, предоставляющих такие услуги, предостаточно.
Как в Ubuntu протестировать жесткий диск на ошибки.
Проверка с помощью встроенного ПО
Совсем необязательно качать программы, чтобы выполнить проверку диска в Ubuntu. Операционная система уже обладает утилитой, которая предназначена для этой задачи. Называется она badblocks, управляется через терминал.
Открываем терминал и вводим:
sudo fdisk -l
Эта команда отображает информацию о всех HDD, которые используются системой.
После этого вводим:
sudo badblocks -sv /dev/sda
Команда служит уже для поиска повреждённых секторов. Вместо /dev/sda вводим имя своего накопителя. Ключи -s и -v служат для того, чтобы отображать в правильном порядке ход проверки блоков (s) и чтобы выдавать отчёт обо всех действиях (v).
Нажатием клавиш Ctrl + C мы останавливаем проверку жёсткого диска.
Для контроля за файловой системой можно также использовать две другие команды.
Для того чтобы размонтировать файловую систему, вводим:
umount /dev/sda
Для проверки и исправления ошибок:
sudo fsck -f -c /dev/sda
- «-f» делает процесс принудительным, то есть проводит его, даже если HDD помечен как работоспособный;
- «-c» находит и помечает бэд-блоки;
- «-y» — дополнительный вводимый аргумент, который сразу же отвечает Yes на все вопросы системы. Вместо него можно ввести «-p», он проведёт проверку в автоматическом режиме.
Программы
Дополнительное программное обеспечение также отлично справляется с этой функцией. А иногда даже лучше. Тем более что некоторым пользователям проще работать с графическим интерфейсом.
GParted
GParted как раз для тех, кому текстовый интерфейс не по душе. Утилита выполняет большое количество задач, связанных с работой HDD на Убунту. В их число входит и проверка диска на ошибки.
Для начала нам нужно скачать и установить GParted. Вводим следующую команду, чтобы выполнить загрузку из официальных репозиториев:
sudo apt-get install gparted
Установить программу легко и при помощи Центра загрузки приложений.
- Открываем приложение. На главном экране сразу же выводятся все носители. Если какой-то из них помечен восклицательным знаком, значит, с ним уже что-то не так.
- Щёлкаем по тому диску, который хотим проверить.
- Жмём на кнопку «Раздел», расположенную сверху.
- Выбираем «Проверка на ошибки».
Программа отсканирует диск. В зависимости от его объёма процесс может идти дольше или меньше. После сканирования мы будем оповещены о его результатах.
Это уже более сложная утилита, которая выполняет более серьёзную проверку HDD по различным параметрам. Как следствие, управлять ей тоже сложнее. Графический интерфейс в Smartmontools не предусмотрен.
Качаем программу:
aptitude install smartmontools
Смотрим, какие накопители подключены к нашей системе. Обращать внимание нужно на строчки, оканчивающиеся буквой, а не цифрой. Именно в этих строках содержится информация о дисках.
ls -l /dev | grep -E ‘sd|hd’
Вбиваем команду для выведения подробной информации о носителе. Стоит посмотреть на параметр ATA. Дело в том, что при замене родного диска, лучше ставить устройство с тем же либо большим ATA. Так можно максимально раскрыть его возможности. А также посмотрите и запомните параметры SMART.
smartctl —info /dev/sde
Запускаем проверку. Если SMART поддерживается, то добавляем «-s». Если он не поддерживается или уже включён, то этот аргумент можно убрать.
smartctl -s on -a /dev/sde
После этого смотрим информацию под READ SMART DATA. Результат может принимать два значения: PASSED или FAILED. Если выпало последнее, можно начинать делать резервные копии и искать замену винчестеру.
Этим возможности программы не исчерпываются. Но для однократной проверки HDD этого будет вполне достаточно.
Safecopy
Это уже та программа, которую впору использовать на тонущем судне. Если мы осведомлены, что с нашим диском что-то не так, и нацелены спасти как можно больше выживших файлов, то Safecopy придёт на помощь. Её задача как раз заключается в копировании данных с повреждённых носителей. Причём она извлекает файлы даже из битых блоков.
Устанавливаем Safecopy:
sudo apt install safecopy
Переносим файлы из одной директории в другую. Выбрать можно любую другую. В данном случае мы переносим данные с диска sda в папку home.
sudo safecopy /dev/sda /home/
Бэд-блоки
У некоторых могут возникнуть вопросы: «что такое эти битые блоки и откуда они, вообще, взялись на моём HDD, если я его ни разу не трогал?» Bad blocks, или бэд-секторы — разделы HDD, которые больше не читаются.
Во всяком случае так они по объективным причинам были помечены файловой системой. И скорее всего, с диском в этих местах действительно что-то не так.
«Бэды» встречаются как на старых винчестерах, так и на самых современных, поскольку работают они практически по тем же самым технологиям.
Появляются же сбойные секторы по разным причинам.
- Прерывание записи из-за отключения питания. Вся информация, поступающая на жёсткий диск, разбивается в виде единиц и нулей на самые разные его части. Сбить этот процесс — значит сильно запутать винчестер.
- Некачественная сборка. Тут и говорить нечего. У дешёвого китайского устройства полететь может что угодно.
Теперь вы знаете, как сканировать HDD на ошибки. Проверка диска как на Ubuntu, так и на других системах довольно важная операция, которую стоит проводить хотя бы раз в год.
Linux, проверка жестких дисков

Рассмотрим способы проверки и диагностики hdd в linux системах. Информация о работе HDD поможет проанализировать состояние и в случае необходимости заменить сбойный носитель, тем самым предотвратив крах системы или потерю данных. Дополнительно прикручиваем наблюдение за smart HDD в нашу систему мониторинга zabbix
Получаем список подключенных накопителей в системе
fdisk -l
Для определения, что и куда смонтированно, выполним
mount
Посмотреть занятое место на том или ином накопителе
df -h
Если есть софт.райд, проверим его следующей командой
root@big:~# cat /proc/mdstat
Personalities : [raid1]
md1 : active raid1 sdb3[0] sda3[1] 965888832 blocks super 1.2 [2/2] [UU]
md0 : active raid1 sdb1[0] sda1[1] 9756544 blocks super 1.2 [2/2] [UU]unused devices:
root@big:~#
[raid1] какой raid установлен (собран)
md0 — название устройства raid
sda[1] sdb[1] — включенные устройства в данный raid
[UU] — состояние дисков в RAID массиве
Устанавливаем необходимые пакеты
aptitude install hdpparm sysstat smartmontools
Смотрим состояние скорости чтения с накопителя
hdparm -t /dev/sda
При помощи iostat (в составе sysstat) анализируем нагрузку на наши HDD
Смотрим вывод данных по всем дискам c интервалом в 10 сек
iostat -x 10
Можно определить накопитель для анализа, добавив
iostat -x /dev/sda
При помощи данной утилиты определим нагрузку на наши устройства, статистику ввода / вывода и процентную утилизацию.
| avg-cpu: | %user | %nice | %system | %iowait | %steal | %idle |
| 0,16 | 0,00 | 1,89 | 23,75 | 0,00 | 74,21 |
Проверка состояния накопителей
Для начала проверим наш HDD на наличие сбойных блоков, в случае необходимости выделим их и пометим для игнорирования.
badblocks /dev/sda3 -sv > /root/badblockSDA3
Checking for bad blocks (read-only test): 27.93% done, 36:12 elapsed. (0/0/0 errors)
/dev/sda3 — имя проверяемого устройства
s — вывод процентной информации
v — включаем подробный режим
> /root/badblockSDA3 — записываем сбойные секторы в файл
Пометка бэд блоков (в дальнейшем помеченные блоки будут игнорироваться системой):
e2fsck -l /root/badblockSDA3 /dev/sda3
Плохие блоки помечены, с диском можно работать.
ВНИМАНИЕ!!! Данная операция должна производиться на размонтированном носителе или в режиме read-only
ВНИМАНИЕ!!! Проверенное устройство и устройство на на котором будут помечаться сбойные блоки должно быть одно и тоже!
Получаем данные S.M.A.R.T о работе HDD
smartctl -a /dev/sdX
Где /dev/sdX — имя устройства которое необходимо проверить.
Вы получите вывод атрибутов S.M.A.R.T., значение каждого из которых хорошо описаны в wiki
Мониторинг S.M.A.R.T состояния жестких дисков в Zabbix
Для каждого из накопителей проверяем поддержку SMART
root@big:~# smartctl -i /dev/sda |grep SMARTSMART support is: Available — device has SMART capability.SMART support is: Enabled
root@big:~#
Если поддерживается но не включен, то включаем
smartctl -s on -S on -o on /dev/sda
проверяем статус командой
smartctl -H /dev/sda |grep «test»| cut -f2 -d: |tr -d » «
root@big:/etc/zabbix# smartctl -H /dev/sda |grep «test»| cut -f2 -d: |tr -d » «
PASSED
root@big:/etc/zabbix#
В конфигурационном файле zabbix агента агента включаем параметр проверки smart для диска
UserParameter=HDD_smart.[*],sudo smartctl -H /dev/$1 |grep «test»| cut -f2 -d: |tr -d » «где HDD_smart — ключ для zabbix элемента
в sudoers добавляем запись
zabbix ALL=NOPASSWD:/usr/sbin/smartctl
рестартуем sudo и zabbix агента.
Дабы быть уверенным в корректности, залогинимся под zabbix пользователем и проверяем выполнение нашей команды
root@big:/etc/zabbix# su — zabbix -s /bin/bashКаталог отсутствует или недоступен, вход в систему выполняется с HOME=/zabbix@big:/$ sudo smartctl -H /dev/sda |grep «test»| cut -f2 -d: |tr -d » «PASSED
zabbix@big:/$
На zabbix сервер создадим zabbix agent (Активный) элемент данных
Имя — произвольное
Тип — Zabbix агент (Активный)
Ключ — HDD_smart.[sda] — для первого диска, для второго соответственно [sdb] …
Тип — Символ
И через некоторое время наблюдаем данные
Далее все по Вашему усмотрению, настраиваем триггеры, оповещение и т.п.
Проверка диска на битые секторы в Linux
Любой компьютер — сложное устройство, которые состоит из множества компонентов и никто не застрахован от сбоев любого из них. В этой статье мы рассмотрим как своевременно распознать одну из серьезных проблем с устройствами хранения информации, будь то жесткий диск или flash-накопитель, как выполняется проверка диска на битые секторы linux.
Любой накопитель состоит из множества маленьких блоков (секторов), которые хранят информацию в виде нулей или единиц (битов). Если, по какой-то причине, операционная система не может записать бит информации в определенный сектор, то можно считать его «битым».
Сектор может стать битым по разным причинам:
- Заводской брак
- Выключение питание компьютера во время записи информации.
- Физический износ накопителя.
Небольшое количество битых секторов находится практически на любом накопителе. Но стоит обратить внимание,если их количество со временем увеличивается. Это может говорить о скорой физической смерти накопителя и Вам пора задуматься о его замене.
Давайте рассмотрим, при помощи каких утилит в Linux мы можем проверить диск на битые секторы linux.
Проверка накопителя на битые секторы средствами badblocks
Badblocks — стандартная утилита Linuх для проверки на битые секторы. Она устанавливается по-умолчанию практически в любой дистрибутив и с ее помощью можно проверить как жесткий диск, так и внешний накопитель.
Для начала давайте посмотрим, какие накопители подключены к нашей системе и какие на них имеются разделы. Для этого нам нужна еще одна стандартная утилита Linux — fdisk.
Естественно, что выполнять команды нужно с правами суперпользователя:
sudo fdisk -l
Параметром -l мы говорим утилите fdisk, что нам нужно показать список разделов и выйти.
Теперь, когда мы знаем, какие разделы у нас есть, мы можем проверить их на битые секторы. Для этого мы будем использовать утилиту badblocks следующим образом:
sudo badblocks -v /dev/sda1 > badsectors.txt
Для проверки мы указываем следующие параметры:
- -v — подробный вывод информации о результатах проверки.
- /dev/sda1 — раздел, который мы хотим проверить на битые секторы.
- > badsectors.txt — выводим результат выполнения команды в файл badsectors.txt.
Если же в результате были найдены битые секторы, то нам надо дать указание операционной системе не записывать в них информацию в будущем. Для этого нам понадобятся утилиты Linux для работы с файловыми системами:
- e2fsck. Если мы будем исправлять раздел с файловыми система Linux ( ext2,ext3,ext4).
- fsck. Если мы будем исправлять файловую систему, отличную от ext.
Вводим следующие команды:
sudo e2fsck -l badsectors.txt /dev/sda1
Или, если у нас файловая система не ext:
sudo fsck -l badsectors.txt /dev/sda1
Параметром -l мы говорим утилите использовать список битых секторов из файла badsectors.txt, который мы получили ранее при проверке с помощью утилиты badblocks.
Теперь давайте рассмотрим более современный и надежный способ проверить диск на битые секторы linux. Современные накопители ATA/SATA ,SCSI/SAS,SSD имеют встроенную систему самоконтроля S.M.A.R.
T (Self-Monitoring, Analysis and Reporting Technology, Технология самоконтроля, анализа и отчетности), которая производит мониторинг параметров накопителя и поможет определить ухудшение параметров работы накопителя на ранних стадиях.
Для работы со S.M.A.R.T в Linux есть утилита smartmontools.
Давайте сначала ее установим. Если ваш дистрибутив основан на DebianUbuntu, то вводите:sudo apt install smartmontools
Если же у Вас дистрибутив на основе RHELCentOS, то вводите:
sudo yum install smartmontools
Теперь, когда мы установили smartmontools мы можем посмотреть станицу помощи, с помощью команды:
man smartctl
или
smartctl -h
Давайте перейдем к работе с утилитой. Вводим следующую команду с параметром -H,чтобы утилита показала нам информацию о состоянии накопителя:
sudo smartctl -H /dev/sda1
Как видим, проверка диска на битые секторы linux завершена и утилита говорит нам, что с накопителем все в порядке!
Дополнительно, можно указать следующие параметры -a или —all, чтобы получить еще больше информации о накопителе, или -x и —xall, чтобы просмотреть информацию в том числе и об остальных параметрах накопителя.
Выводы
В этой статье мы рассмотрели способы проверки накопителей на наличие битых секторов под Linux для того,чтобы вовремя предусмотреть возможные сбои и не потерять данные.
Проверка жесткого диска в linux
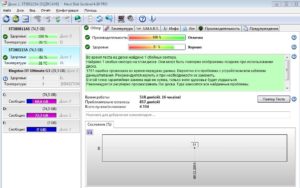
Если и есть то, с чем вы очень не хотите столкнуться в вашей операционной системе, то это точно неожиданный выход из строя жестких дисков. С помощью резервного копирования и технологии хранения RAID вы можете очень быстро вернуть все данные на место, но потеря аппаратного устройства может очень сильно сказаться на бюджете, особенно если вы такого не планировали.
Чтобы избежать таких проблем можно использовать smartmontools. Это программный пакет для управления и мониторинга устройств хранения данных с помощью технологии Self-Monitoring Analysis and Reporting Technology или просто SMART.
Большинство современных ATA / SATA, SCSI / SAS накопителей информации предоставляют интерфейс SMART.
Цель SMART — мониторинг надежности жесткого диска, для выявления различных ошибок и своевременного реагирования на их появление. Smartmontools состоит из двух утилит — smartctl и smartd.
Вместе они представляют мощную систему мониторинга и предупреждения о возможных поломках HDD в Linux. Дальше будет подробно рассмотрена проверка жесткого диска linux.
Пакет smartmontools есть в официальных репозиториях большинства дистрибутивов Linux, поэтому установка сводится к выполнению одной команды. В Debian и основанных на нем системах выполните:
aptitude install smartmontools
А для Red Hat:
yum install smartmontools
Теперь можно переходить к диагностике жесткого диска linux.
Проверка жесткого диска в smartctl
Сначала узнайте какие жесткие диски подключены к вашей системе:
ls -l /dev | grep -E 'sd|hd'
В выводе будет что-то подобное:
Здесь — sdx — имя устройства HDD подключенного к компьютеру.
Для отображения информации о конкретном жестком диске (модель устройства, S/N, версия прошивки, версия ATA, доступность интерфейса SMART) Запустите smartctl с опцией info и именем жесткого диска. Например, для /dev/sda:
smartctl —info /dev/sda
Хотя вы можете и не обратить внимание на версию ATA, это один из самых важных факторов при поиске замены устройству. Каждая новая версия ATA совместима с предыдущими.
Например, старые устройства ATA-1 и ATA-2 прекрасно будут работать на ATA-6 и ATA-7 интерфейсах, но не наоборот. Когда версии ATA устройства и интерфейса не совпадают, возможности оборудования не будут полностью раскрыты.
В данном случае для замены лучше всего выбрать жесткий диск ATA-7.
Запустить проверку жесткого диска ubuntu можно командой:
smartctl -s on -a /dev/sda
Здесь опция -s включает флаг SMART на указном устройстве. Вы можете его убрать если поддержка SMART уже включена. Информация о диске разделена на несколько разделов, В разделе READ SMART DATA находится общая информация о здоровье жесткого диска.=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment rest result: PASSED
Этот тест может быть пройден (PASSED) или нет (FAILED). В последнем случае сбой неизбежен, начинайте резервное копирование данных с этого диска.
Следующая вещь которую можно посмотреть, когда нужна диагностика HDD в linux, это таблица SMART атрибутов.
В SMART таблице записаны параметры, определенные для конкретного диска разработчиком, а также порог отказа для этих параметров. Таблица заполняется автоматически и обновляется на основе прошивки диска.
- ID # — ID атрибута, как правило, десятичное число между 1 и 255;
- ATTRIBUTE_NAME — Название атрибута;
- FLAG — флаг обработки атрибута;
- VALUE — это поле представляет нормальное значение для состояния данного атрибута в диапазоне от 1 до 253, 253 — лучшее состояние, 1 — худшее. В зависимости от свойств, начальное значение может быть от 100 до 200;
- WORST — худшее значение value за все время;
- THRESH — самое низкое значение value, после перехода за которое нужно сообщить что диск непригоден для эксплуатации;
- TYPE — тип атрибута, может быть Pre-fail или Old_age. Все атрибуты по умолчанию считаются критическими, то-есть если диск не прошел проверку по одному из атрибутов, то он уже считается не пригодным (FAILED) но атрибуты old_age не критичны;
- UPDATED — показывает частоту обновления атрибута;
- WHEN_FAILED — будет установлено в FAILING_NOW если значение атрибута меньше или равно THRESH, или в «-» если выше. В случае FAILING_NOW, лучше как можно скорее выполнить резервное копирование, особенно если тип атрибута Pre-fail.
- RAW_VALUE — значение, определенное производителем.
Сейчас вы думаете, да smartctl хороший инструмент, но у меня нет возможности запускать его каждый раз вручную, было бы неплохо автоматизировать все это дело чтобы программа запускалась периодически и сообщала мне о результатах проверки. И это возможно, с помощью smartd.
Настройка smartd и smartctl для диагностики и мониторинга в реальном времени
Диагностика hdd в linux в реальном времени настраивается очень просто. Сначала отредактируйте файл конфигурации smartd — /etc/smartd.conf. Добавьте следующую строку:
nano /etc/smartd.conf
/dev/sda -m myemail@mydomain.com -M test
- -m — адрес электронной почты для отправки результатов проверки. Это может быть адрес локального пользователя, суперпользователя или внешний адрес, если настроен сервер для отправки электронной почты;
- -M — частота отправки писем. once — отправлять только одно сообщение о проблемах с диском. daily — отправлять сообщения каждый день если была обнаружена проблема. diminishing — отправлять сообщения через день если была обнаружена проблема. test — отправлять тестовое сообщение при запуске smartd. exec — выполняет указанную программу в место отправки почты.
Сохраните изменения и перезапустите smartd. Вы должны получить на электронную почту письмо подобного содержания:
Также можно запланировать тесты по своему графику, для этого используйте опцию -s и регулярное выражение типа «T/MM/ДД/ДН/ЧЧ», где:
- T — тип теста:
- L — длинный тест;
- S — короткий тест;
- C — тест перемещение (ATA);
- O — оффлайн (тест).
Остальные символы определяют дату и время теста:
- ММ — месяц в году;
- ДД — день месяца;
- ЧЧ — час дня;
- ДН — день недели (от 1 — понедельник 7 — воскресенье;
- MM, ДД и ЧЧ — указываются с двух десятичных цифр.
Точка означает все возможные значения, выражение в скобках (A|B|C) — означает один из трех вариантов, выражение в квадратных скобках [1-5] означает диапазон (от 1 до 5).
Например, чтобы выполнять полную проверку жесткого диска linux каждый рабочий день в час дня добавьте следующую строку в smartd.conf:
Проверка состояния накопителей в Linux
Проверка и анализ состояния накопителей в Linux с помощью консольных утилит badblocks, smartmontools и графической программы GSmartControl
Типы накопителей:
- Встроенные жёсткие диски;
- USB-флеш-накопители (сленг. флешка);
Проверка накопителей средствами badblocks
Утилита badblocks установлена по-умолчанию.
Для просмотра подключенных накопителей и разделов на них, введите команду:
Для проверки накопителя на битые сектора, выполнить команду:
sudo badblocks -v /dev/sdX > badblocks.txt.txt
-v — отображение подробной информации во время работы программы
/dev/sdX — имя устройства, которое необходимо проверить
> badblocks.txt — запись результатов проверки (сохраняется в домашней папке: /home/user)
При наличии битых секторов, можно воспользоваться утилитами: e2fsck (ext2, ext3, ext4), fsck (отличные от ext) для игнорирования системой битых секторов:
sudo e2fsck -l badblocks.txt /dev/sdX
sudo fsck -l badblocks.txt /dev/sdX
Проверка состояния накопителей при помощи S.M.A.R.T
Установка:
sudo apt-get install smartmontools
Для проверки накопителя на битые сектора при помощи S.M.A.R.T., выполнить команду:
sudo smartctl -a /dev/sdX
/dev/sdX — имя устройства, которое необходимо проверить
Проверка состояния накопителей при помощи GSmartControl
Чтобы установить самую свежую стабильную версию GSmartControl в Ubuntu, можно воспользоваться PPA репозиторием. Для этого выполните последовательно в терминале команды:
Установить через центр приложений
Работа с программой:
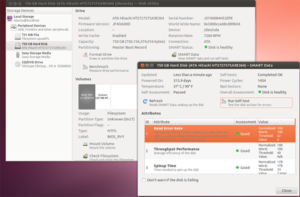
Выбираем диск и кликаем левой клавишей мыши 2 раза или выбираем диск, потом идём в меню, там жмём на Device, далее жмём View details, далее жмём на вкладку Attributes:
Анализ параметров, выводимых программой
Каждый атрибут имеет величину Value. Value Изменяется в диапазоне от 0 до 255 задается производителем). Низкое значение говорит о быстрой деградации диска или о возможном скором сбое. т.е. чем выше значение Value атрибута, тем лучше. Raw Value — это значение атрибута во внутреннем формате производителя значение малоинформативно для всех кроме сервисманов.
Threshold — минимальное возможное значение атрибута, при котором гарантируется безотказная работа накопителя. SMART. Смотрим состояние жесткого диска. Если VALUE стало меньше THRESH — Атрибут считается failed и отображается в столбце WHEN_FAILED. При значении атрибута меньше Threshold очень вероятен сбой в работе или полный отказ. WORST- минимальное нормализованное значение.
Это минимальное значение, которое достигалось с момента включения SMART на диске. Атрибуты бывают критически важными (Pre-fail) и некритически важными (Old_age).
Выход критически важного параметра за пределы Threshold фактический означает выход диска из строя, выход за пределы допустимых значений не критически важного параметра свидетельствует о наличии проблемы, но диск может сохранять свою работоспособность.
Критичные атрибуты
Raw Read Error Rate — частота ошибок при чтении данных с диска, происхождение которых обусловлено аппаратной частью диска.
Spin Up Time — время раскрутки пакета дисков из состояния покоя до рабочей скорости. При расчете нормализованного значения (Value) практическое время сравнивается с некоторой эталонной величиной, установленной на заводе.
Не ухудшающееся не максимальное значение при Spin Up Retry Count Value = max (Raw равном 0) не говорит ни о чем плохом. Отличие времени от эталонного может быть вызвано рядом причин, например просадка по вольтажу блока питания.
Spin Up Retry Count — число повторных попыток раскрутки дисков до рабочей скорости, в случае если первая попытка была неудачной. Ненулевое значение Raw (соответственно не максимальное Value) свидетельствует о проблемах в механической части накопителя.Seek Error Rate — частота ошибок при позиционировании блока головок. Высокое значение Raw свидетельствует о наличии проблем, которыми могут являться повреждение сервометок, чрезмерное термическое расширение дисков, механические проблемы в блоке позиционирования и др. Постоянное высокое значение Value говорит о том, что все хорошо.
Reallocated Sector Count — число операций переназначения секторов. SMART в современных дисках способен произвести анализ сектора на стабильность работы «на лету» и в случае признания его сбойным, произвести его переназначение.
Некритичные атрибуты:
Start/Stop Count — полное число запусков/остановов шпинделя. Гарантировано мотор диска способен перенести лишь определенное число включений/выключений. Это значение выбирается в качестве Treshold. Первые модели дисков со скоростью вращения 7200 оборотов/мин имели ненадежный двигатель, могли перенести лишь небольшое их число и быстро выходили из строя.
Power On Hours — число часов проведенных во включенном состоянии. В качестве порогового значения для него выбирается паспортное время наработки на отказ (MTBF). Обычно величина MTBF огромна, и маловероятно, что этот параметр достигнет критического порога. Но даже в этом случае выход из строя диска совершенно не обязателен.
Drive Power Cycle Count — количество полных циклов включения-выключения диска. По этому и предыдущему атрибуту можно оценить, например, сколько использовался диск до покупки.
Temperatue — Здесь хранятся показания встроенного термодатчика. Температура имеет огромное влияние на срок службы диска (даже если она находится в допустимых пределах). Вернее имеет влияние не на срок службы диска а на частоту возникновения некоторых типов ошибок, которые влияют на срок службы.
Current Pending Sector Count — Число секторов, являющихся кандидатами на замену. Они не были ещё определены как плохие, но считывание их отличается от чтения стабильного сектора, так называемые подозрительные или нестабильные сектора.
Uncorrectable Sector Count — число ошибок при обращении к сектору, которые не были скорректированы. Возможными причинами возникновения могут быть сбои механики или порча поверхности.
UDMA CRC Error Rate — число ошибок, возникающих при передаче данных по внешнему интерфейсу. Могут быть вызваны некачественными кабелями, нештатными режимами работы.
Write Error Rate — показывает частоту ошибок происходящих при записи на диск. Может служить показателем качества поверхности и механики накопителя.