
Как найти корреляцию в Excel
Задача №3. Расчёт параметров регрессии и корреляции с помощью Excel

По территориям региона приводятся данные за 200Х г.
| 78 | 133 |
| 82 | 148 |
| 87 | 134 |
| 79 | 154 |
| 89 | 162 |
| 106 | 195 |
| 67 | 139 |
| 88 | 158 |
| 73 | 152 |
| 87 | 162 |
| 76 | 159 |
| 115 | 173 |
Задание:
1. Постройте поле корреляции и сформулируйте гипотезу о форме связи.
2. Рассчитайте параметры уравнения линейной регрессии
.
3. Оцените тесноту связи с помощью показателей корреляции и детерминации.
4. Дайте с помощью среднего (общего) коэффициента эластичности сравнительную оценку силы связи фактора с результатом.
5. Оцените с помощью средней ошибки аппроксимации качество уравнений.
6. Оцените с помощью F-критерия Фишера статистическую надёжность результатов регрессионного моделирования.
7. Рассчитайте прогнозное значение результата, если прогнозное значение фактора увеличится на 10% от его среднего уровня. Определите доверительный интервал прогноза для уровня значимости .
8. Оцените полученные результаты, выводы оформите в аналитической записке.
Решение:
Решим данную задачу с помощью Excel.
1.
Сопоставив имеющиеся данные х и у, например, ранжировав их в порядке возрастания фактора х, можно наблюдать наличие прямой зависимости между признаками, когда увеличение среднедушевого прожиточного минимума увеличивает среднедневную заработную плату. Исходя из этого, можно сделать предположение, что связь между признаками прямая и её можно описать уравнением прямой. Этот же вывод подтверждается и на основе графического анализа.
Чтобы построить поле корреляции можно воспользоваться ППП Excel. Введите исходные данные в последовательности: сначала х, затем у.
Выделите область ячеек, содержащую данные.
Затем выберете: Вставка / Точечная диаграмма / Точечная с маркерами как показано на рисунке 1.
Рисунок 1 Построение поля корреляции
Анализ поля корреляции показывает наличие близкой к прямолинейной зависимости, так как точки расположены практически по прямой линии.2. Для расчёта параметров уравнения линейной регрессии
воспользуемся встроенной статистической функцией ЛИНЕЙН.
Для этого:
1) Откройте существующий файл, содержащий анализируемые данные; 2) Выделите область пустых ячеек 5×2 (5 строк, 2 столбца) для вывода результатов регрессионной статистики.
3) Активизируйте Мастер функций: в главном меню выберете Формулы / Вставить функцию.
4) В окне Категория выберете Статистические, в окне функция – ЛИНЕЙН. Щёлкните по кнопке ОК как показано на Рисунке 2;
Рисунок 2 Диалоговое окно «Мастер функций»
5) Заполните аргументы функции:
Известные значения у – диапазон, содержащий данные результативного признака;
Известные значения х – диапазон, содержащий данные факторного признака;
Константа – логическое значение, которое указывает на наличие или на отсутствие свободного члена в уравнении; если Константа = 1, то свободный член рассчитывается обычным образом, если Константа = 0, то свободный член равен 0;
Статистика – логическое значение, которое указывает, выводить дополнительную информацию по регрессионному анализу или нет. Если Статистика = 1, то дополнительная информация выводится, если Статистика = 0, то выводятся только оценки параметров уравнения.
Щёлкните по кнопке ОК;
Рисунок 3 Диалоговое окно аргументов функции ЛИНЕЙН
6) В левой верхней ячейке выделенной области появится первый элемент итоговой таблицы. Чтобы раскрыть всю таблицу, нажмите на клавишу , а затем на комбинацию клавиш ++.
Дополнительная регрессионная статистика будет выводиться в порядке, указанном в следующей схеме:
| Значение коэффициента b | Значение коэффициента a |
| Стандартная ошибка b | Стандартная ошибка a |
| Коэффициент детерминации R2 | Стандартная ошибка y |
| F-статистика | Число степеней свободы df |
| Регрессионная сумма квадратов | Остаточная сумма квадратов |
Рисунок 4 Результат вычисления функции ЛИНЕЙН
Получили уровнение регрессии:
Делаем вывод: С увеличением среднедушевого прожиточного минимума на 1 руб. среднедневная заработная плата возрастает в среднем на 0,92 руб.
3. Коэффициент детерминации означает, что 52% вариации заработной платы (у) объясняется вариацией фактора х – среднедушевого прожиточного минимума, а 48% — действием других факторов, не включённых в модель.
По вычисленному коэффициенту детерминации можно рассчитать коэффициент корреляции: .
Связь оценивается как тесная.
4. С помощью среднего (общего) коэффициента эластичности определим силу влияния фактора на результат.Для уравнения прямой средний (общий) коэффициент эластичности определим по формуле:
Средние значения найдём, выделив область ячеек со значениями х, и выберем Формулы / Автосумма / Среднее, и то же самое произведём со значениями у.
Рисунок 5 Расчёт средних значений функции и аргумент
Таким образом, при изменении среднедушевого прожиточного минимума на 1% от своего среднего значения среднедневная заработная плата изменится в среднем на 0,51%.
С помощью инструмента анализа данных Регрессия можно получить:- результаты регрессионной статистики, — результаты дисперсионного анализа, — результаты доверительных интервалов, — остатки и графики подбора линии регрессии,
— остатки и нормальную вероятность.
Порядок действий следующий:
1) проверьте доступ к Пакету анализа. В главном меню последовательно выберите: Файл/Параметры/Надстройки.
2) В раскрывающемся списке Управление выберите пункт Надстройки Excel и нажмите кнопку Перейти.
3) В окне Надстройки установите флажок Пакет анализа, а затем нажмите кнопку ОК.
• Если Пакет анализа отсутствует в списке поля Доступные надстройки, нажмите кнопку Обзор, чтобы выполнить поиск.
• Если выводится сообщение о том, что пакет анализа не установлен на компьютере, нажмите кнопку Да, чтобы установить его.
4) В главном меню последовательно выберите: Данные / Анализ данных / Инструменты анализа / Регрессия, а затем нажмите кнопку ОК.5) Заполните диалоговое окно ввода данных и параметров вывода:
Входной интервал Y – диапазон, содержащий данные результативного признака;
Входной интервал X – диапазон, содержащий данные факторного признака;
Метки – флажок, который указывает, содержит ли первая строка названия столбцов или нет;
Константа – ноль – флажок, указывающий на наличие или отсутствие свободного члена в уравнении;
Выходной интервал – достаточно указать левую верхнюю ячейку будущего диапазона;
6) Новый рабочий лист – можно задать произвольное имя нового листа.
Затем нажмите кнопку ОК.
Рисунок 6 Диалоговое окно ввода параметров инструмента Регрессия
Результаты регрессионного анализа для данных задачи представлены на рисунке 7.
Рисунок 7 Результат применения инструмента регрессия
5. Оценим с помощью средней ошибки аппроксимации качество уравнений. Воспользуемся результатами регрессионного анализа представленного на Рисунке 8.
Рисунок 8 Результат применения инструмента регрессия «Вывод остатка»
Составим новую таблицу как показано на рисунке 9. В графе С рассчитаем относительную ошибку аппроксимации по формуле:
Рисунок 9 Расчёт средней ошибки аппроксимации
Средняя ошибка аппроксимации рассчитывается по формуле:
Качество построенной модели оценивается как хорошее, так как не превышает 8 – 10%.
6. Из таблицы с регрессионной статистикой (Рисунок 4) выпишем фактическое значение F-критерия Фишера:
Поскольку при 5%-ном уровне значимости, то можно сделать вывод о значимости уравнения регрессии (связь доказана).8. Оценку статистической значимости параметров регрессии проведём с помощью t-статистики Стьюдента и путём расчёта доверительного интервала каждого из показателей.
Выдвигаем гипотезу Н0 о статистически незначимом отличии показателей от нуля:
.
для числа степеней свободы
На рисунке 7 имеются фактические значения t-статистики:
t-критерий для коэффициента корреляции можно рассчитать двумя способами:
I способ:
где – случайная ошибка коэффициента корреляции.
Данные для расчёта возьмём из таблицы на Рисунке 7.
II способ:
Фактические значения t-статистики превосходят табличные значения:
Поэтому гипотеза Н0 отклоняется, то есть параметры регрессии и коэффициент корреляции не случайно отличаются от нуля, а статистически значимы.
Доверительный интервал для параметра a определяется как
Для параметра a 95%-ные границы как показано на рисунке 7 составили:
Доверительный интервал для коэффициента регрессии определяется как
Для коэффициента регрессии b 95%-ные границы как показано на рисунке 7 составили:
Анализ верхней и нижней границ доверительных интервалов приводит к выводу о том, что с вероятностью параметры a и b, находясь в указанных границах, не принимают нулевых значений, т.е. не являются статистически незначимыми и существенно отличны от нуля.
7. Полученные оценки уравнения регрессии позволяют использовать его для прогноза. Если прогнозное значение прожиточного минимума составит:
Тогда прогнозное значение прожиточного минимума составит:
Ошибку прогноза рассчитаем по формуле:
где
Дисперсию посчитаем также с помощью ППП Excel. Для этого:
1) Активизируйте Мастер функций: в главном меню выберете Формулы / Вставить функцию.
2) В окне Категория выберете Статистические, в окне функция – ДИСП.Г. Щёлкните по кнопке ОК.
3) Заполните диапазон, содержащий числовые данные факторного признака. Нажмите ОК.
Рисунок 10 Расчёт дисперсии
Получили значение дисперсии
Для подсчёта остаточной дисперсии на одну степень свободы воспользуемся результатами дисперсионного анализа как показано на Рисунке 7.
Доверительные интервалы прогноза индивидуальных значений у при с вероятностью 0,95 определяются выражением:Интервал достаточно широк, прежде всего, за счёт малого объёма наблюдений. В целом выполненный прогноз среднемесячной заработной платы оказался надёжным.
Условие задачи взято из: Практикум по эконометрике: Учеб. пособие / И.И. Елисеева, С.В. Курышева, Н.М. Гордеенко и др.; Под ред. И.И. Елисеевой. – М.: Финансы и статистика, 2003. – 192 с.: ил.
Функция КОРРЕЛ для определения взаимосвязи и корреляции в Excel
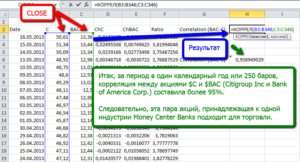
Функция КОРРЕЛ в Excel используется для расчета коэффициента корреляции между для двух исследуемых массивов данных и возвращает соответствующее числовое значение.
Пример 1. В таблице Excel содержатся данные о курсе доллара и средней зарплате сотрудников фирмы на протяжении нескольких лет. Определить взаимосвязь между курсом валюты и средней зарплатой.
Таблица данных:
Формула для расчета:
Описание аргументов:
- B3:B13 – диапазон ячеек, в которых хранятся данные о среднем курсе доллара;
- C3:C13 – диапазон ячеек со значениями средней зарплаты.
Результат расчетов:
Полученный результат близок к 1 и свидетельствует о сильной прямой взаимосвязи между исследуемыми величинами. Однако прямо пропорциональной зависимости между ними нет, то есть на увеличение средней зарплаты оказывали влияние и прочие факторы.
Пример 2. Два сильных кандидата на руководящий пост воспользовались услугами двух различных пиар-агентств для запуска предвыборной компании, которая длилась 15 дней.
Ежедневно проводился соцопрос независимыми исследователями, которые определяли процент поддержки одного и второго кандидата. Респонденты могли отдавать предпочтение первому, второму кандидату или выступать против обоих.
Определить, насколько влияла каждая предвыборная кампания на степень поддержки кандидатов, какая из них оказалась более эффективной?
Исходные данные:
Произведем расчет коэффициентов корреляции с помощью формул:
=КОРРЕЛ(A3:A17;B3:B17)
=КОРРЕЛ(A3:A17;C3:C17)
Описание аргументов:
- A3:A17 – массив ячеек, содержащий номера дней предвыборной кампании;
- B3:B17 и C3:C17 – диапазон ячеек, содержащие данные о проценте поддержки первого и второго кандидатов соответственно.
Полученные результаты:
Как видно, уровень поддержки первого кандидата увеличивался с каждым днем кампании, поэтому коэффициент корреляции в первом случае стремится к единице. На старте кампании второй кандидат имел больший процент поддержки, и это значение на протяжении первых пяти дней демонстрировало положительную динамику изменений.
Однако затем уровень поддержки стал снижаться, и к 15-му дню упал ниже начального значения. Отрицательное значение коэффициента корреляции свидетельствует о негативном эффекте кампании. Однако на события могли оказывать влияние различные факторы, например, опубликованные компрометирующие материалы. В связи с этим полагаться только на значение коэффициента корреляции в данном случае нельзя.
То есть, коэффициент корреляции не характеризует причинно-наследственную связь.
Анализ популярности контента по корреляции просмотров и репостов видео
Пример 3. Владелец канала использует социальную сеть для рекламы своих роликов. Он заметил, что между числом просмотров и количеством репостов в социальной сети существует некоторая взаимосвязь.
Можно ли спрогнозировать виральность контента канала в Excel? Определить целесообразность использования уравнения линейной регрессии для предсказания количества просмотров роликов в зависимости от числа репостов.
Исходные данные:
Определим наличие взаимосвязи между двумя параметрами по формуле:
Если модуль коэффициента корреляции больше 0,7, считается рациональным использование функции линейной регрессии (y=ax+b) для описания связи между двумя величинами. В данном случае:
Построим график зависимости числа просмотров от количества репостов, отобразим линию тренда и ее уравнение:
Используем данное уравнение для определения количества просмотров при 200, 500 и 1000 репостов:
=9,2937*D4-206,12
Полученные результаты:
Аналогичное уравнение использует функция ПРЕДСКАЗ. То есть, чтобы найти количество просмотров в случае, если было сделано, например, 250 репостов, можно использовать формулу:Полученный результат:
Коэффициент корреляции – один из множества статистических критериев определения наличия взаимосвязи между двумя рядами значений. Для построения точных статистических моделей рекомендуется использовать дополнительные параметры, такие как коэффициент детерминации, стандартная ошибка и другие.
Особенности использования функции КОРРЕЛ в Excel
Функция КОРРЕЛ имеет следующий синтаксис:
=КОРРЕЛ(массив1;массив2)
Описание аргументов:
- массив1 – обязательный аргумент, содержащий диапазон ячеек или массив данных, которые характеризуют изменения свойства какого-либо объекта.
- массив2 – обязательный аргумент (диапазон ячеек либо массив), элементы которого характеризуют изменение свойств второго объекта.
Примечания 1:
- Функция КОРРЕЛ не учитывает в расчетах элементы массива или ячейки из выбранного диапазона, в которых содержатся данные текстового или логического типов. Пустые ячейки также игнорируются. Текстовые представления числовых значений учитываются.
- Если необходимо учесть логические ИСТИНА или ЛОЖЬ в качестве числовых значений 1 или 0 соответственно, можно выполнить явное преобразование данных используя двойное отрицание «—».
- Размерности массив1 и массив2 или количество ячеек, переданных в качестве этих двух аргументов, должны совпадать. Если аргументы содержат разное количество точек данных, например, =КОРРЕЛ({1;2;3};{4;6;8;10}), результатом выполнения функции будет код ошибки #Н/Д.
- Если один из аргументов представляет собой пустой массив или массив нулевых значений, функция КОРРЕЛ вернет код ошибки #ДЕЛ/0!. Аналогичный результат выполнения данной функции будет достигнут в случае, если стандартное отклонение распределения величин в одном из массивов (массив1, массив2) равно 0 (нулю).
- Функция КОРРЕЛ производит расчет коэффициента корреляции по следующей формуле:
Примечание 2: Коэффициент корреляции представляет собой количественную характеристику степени взаимосвязи между двумя свойствами объектов. Этот коэффициент может принимать значения из диапазона от -1 до 1, при этом:
- Если значение коэффициента приближается к 1 или -1, между двумя исследуемыми свойствами существует сильная прямая или обратная взаимосвязи соответственно.
- Если значение коэффициента стремится к 0,5 или -0,5, два свойства слабо прямо или обратно взаимосвязаны друг с другом соответственно.
- Если коэффициент корреляции близок к 0 (нулю), между двумя исследуемыми свойствами отсутствует прямая либо обратная взаимосвязи.
Примечание 3: Для понимания смысла коэффициента корреляции можно привести два простых примера:
- При нагреве вещества количество теплоты, содержащееся в нем, будет увеличиваться. То есть, между температурой и количеством теплоты (физическая величина) существует прямая взаимосвязь.
- При увеличении стоимости продукции спрос на нее уменьшается. То есть, между ценой и покупательной способностью существует обратная взаимосвязь.
2 способа корреляционного анализа в Microsoft Excel
Корреляционный анализ – популярный метод статистического исследования, который используется для выявления степени зависимости одного показателя от другого. В Microsoft Excel имеется специальный инструмент, предназначенный для выполнения этого типа анализа. Давайте выясним, как пользоваться данной функцией.
Скачать последнюю версию Excel
Суть корреляционного анализа
Предназначение корреляционного анализа сводится к выявлению наличия зависимости между различными факторами. То есть, определяется, влияет ли уменьшение или увеличение одного показателя на изменение другого.
Если зависимость установлена, то определяется коэффициент корреляции. В отличие от регрессионного анализа, это единственный показатель, который рассчитывает данный метод статистического исследования. Коэффициент корреляции варьируется в диапазоне от +1 до -1.
При наличии положительной корреляции увеличение одного показателя способствует увеличению второго. При отрицательной корреляции увеличение одного показателя влечет за собой уменьшение другого. Чем больше модуль коэффициента корреляции, тем заметнее изменение одного показателя отражается на изменении второго.
При коэффициенте равном 0 зависимость между ними отсутствует полностью.
Расчет коэффициента корреляции
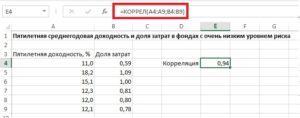
Теперь давайте попробуем посчитать коэффициент корреляции на конкретном примере. Имеем таблицу, в которой помесячно расписана в отдельных колонках затрата на рекламу и величина продаж. Нам предстоит выяснить степень зависимости количества продаж от суммы денежных средств, которая была потрачена на рекламу.
Способ 1: определение корреляции через Мастер функций
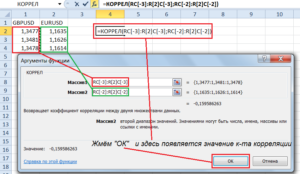
Одним из способов, с помощью которого можно провести корреляционный анализ, является использование функции КОРРЕЛ. Сама функция имеет общий вид КОРРЕЛ(массив1;массив2).
- Выделяем ячейку, в которой должен выводиться результат расчета. Кликаем по кнопке «Вставить функцию», которая размещается слева от строки формул.
- В списке, который представлен в окне Мастера функций, ищем и выделяем функцию КОРРЕЛ. Жмем на кнопку «OK».
- Открывается окно аргументов функции. В поле «Массив1» вводим координаты диапазона ячеек одного из значений, зависимость которого следует определить. В нашем случае это будут значения в колонке «Величина продаж». Для того, чтобы внести адрес массива в поле, просто выделяем все ячейки с данными в вышеуказанном столбце.
В поле «Массив2» нужно внести координаты второго столбца. У нас это затраты на рекламу. Точно так же, как и в предыдущем случае, заносим данные в поле.
Жмем на кнопку «OK».
Как видим, коэффициент корреляции в виде числа появляется в заранее выбранной нами ячейке. В данном случае он равен 0,97, что является очень высоким признаком зависимости одной величины от другой.
Способ 2: вычисление корреляции с помощью пакета анализа
Кроме того, корреляцию можно вычислить с помощью одного из инструментов, который представлен в пакете анализа. Но прежде нам нужно этот инструмент активировать.
- Переходим во вкладку «Файл».
- В открывшемся окне перемещаемся в раздел «Параметры».
- Далее переходим в пункт «Надстройки».
- В нижней части следующего окна в разделе «Управление» переставляем переключатель в позицию «Надстройки Excel», если он находится в другом положении. Жмем на кнопку «OK».
- В окне надстроек устанавливаем галочку около пункта «Пакет анализа». Жмем на кнопку «OK».
- После этого пакет анализа активирован. Переходим во вкладку «Данные». Как видим, тут на ленте появляется новый блок инструментов – «Анализ». Жмем на кнопку «Анализ данных», которая расположена в нем.
- Открывается список с различными вариантами анализа данных. Выбираем пункт «Корреляция». Кликаем по кнопке «OK».
- Открывается окно с параметрами корреляционного анализа. В отличие от предыдущего способа, в поле «Входной интервал» мы вводим интервал не каждого столбца отдельно, а всех столбцов, которые участвуют в анализе. В нашем случае это данные в столбцах «Затраты на рекламу» и «Величина продаж».
Параметр «Группирование» оставляем без изменений – «По столбцам», так как у нас группы данных разбиты именно на два столбца. Если бы они были разбиты построчно, то тогда следовало бы переставить переключатель в позицию «По строкам».
В параметрах вывода по умолчанию установлен пункт «Новый рабочий лист», то есть, данные будут выводиться на другом листе. Можно изменить место, переставив переключатель. Это может быть текущий лист (тогда вы должны будете указать координаты ячеек вывода информации) или новая рабочая книга (файл).
Когда все настройки установлены, жмем на кнопку «OK».
Так как место вывода результатов анализа было оставлено по умолчанию, мы перемещаемся на новый лист. Как видим, тут указан коэффициент корреляции. Естественно, он тот же, что и при использовании первого способа – 0,97. Это объясняется тем, что оба варианта выполняют одни и те же вычисления, просто произвести их можно разными способами.
Как видим, приложение Эксель предлагает сразу два способа корреляционного анализа. Результат вычислений, если вы все сделаете правильно, будет полностью идентичным.
Но, каждый пользователь может выбрать более удобный для него вариант осуществления расчета. Мы рады, что смогли помочь Вам в решении проблемы.
Опишите, что у вас не получилось.
Наши специалисты постараются ответить максимально быстро.
Помогла ли вам эта статья?
ДА НЕТ
Корреляция и ковариация в MS EXCEL
Вычислим коэффициент корреляции и ковариацию для разных типов взаимосвязей случайных величин.
Коэффициент корреляции (критерий корреляцииПирсона, англ. Pearson Product Moment correlation coefficient) определяет степень линейной взаимосвязи между случайными величинами.
где Е[…] – оператор математического ожидания, μ и σ – среднее случайной величины и ее стандартное отклонение.
Как следует из определения, для вычисления коэффициента корреляции требуется знать распределение случайных величин Х и Y. Если распределения неизвестны, то для оценки коэффициента корреляции используется выборочный коэффициент корреляции r (еще он обозначается какRxyилиrxy):
где Sx – стандартное отклонение выборки случайной величины х, вычисляемое по формуле:
Как видно из формулы для расчета корреляции, знаменатель (произведение стандартных отклонений) просто нормирует числитель таким образом, что корреляция оказывается безразмерным числом от -1 до 1.
Корреляция и ковариация предоставляют одну и туже информацию (если известны стандартные отклонения), но корреляцией удобнее пользоваться, т.к. она является безразмерной величиной.
Рассчитать коэффициент корреляции и ковариацию выборки в MS EXCEL не представляет труда, так как для этого имеются специальные функции КОРРЕЛ() и КОВАР(). Гораздо сложнее разобраться, как интерпретировать полученные значения, большая часть статьи посвящена именно этому.
Теоретическое отступление
Напомним, что корреляционной связью называют статистическую связь, состоящую в том, что различным значениям одной переменной соответствуют различные средние значения другой (с изменением значения Х среднее значение Y изменяется закономерным образом). Предполагается, что обе переменные Х и Y являются случайными величинами и имеют некий случайный разброс относительно их среднего значения.
Примечание. Если случайную природу имеет только одна переменная, например, Y, а значения другой являются детерминированными (задаваемыми исследователем), то можно говорить только о регрессии.
Таким образом, например, при исследовании зависимости среднегодовой температуры нельзя говорить о корреляции температуры и года наблюдения и, соответственно, применять показатели корреляции с соответствующей их интерпретацией.
Корреляционная связь между переменными может возникнуть несколькими путями:
- Наличие причинной зависимости между переменными. Например, количество инвестиций в научные исследования (переменная Х) и количество полученных патентов (Y). Первая переменная выступает как независимая переменная (фактор), вторая — зависимая переменная (результат). Необходимо помнить, что зависимость величин обуславливает наличие корреляционной связи между ними, но не наоборот.
- Наличие сопряженности (общей причины). Например, с ростом организации растет фонд оплаты труда (ФОТ) и затраты на аренду помещений. Очевидно, что неправильно предполагать, что аренда помещений зависит от ФОТ. Обе этих переменных во многих случаях линейно зависят от количества персонала.
- Взаимовлияние переменных (при изменении одной, вторая переменная изменяется, и наоборот). При таком подходе допустимы две постановки задачи; любая переменная может выступать как в роли независимой переменной и в роли зависимой.
Таким образом, показатель корреляции показывает, насколько сильна линейная взаимосвязь между двумя факторами (если она есть), а регрессия позволяет прогнозировать один фактор на основе другого.
Корреляция, как и любой другой статистический показатель, при правильном применении может быть полезной, но она также имеет и ограничения по использованию.
Если диаграмма рассеяния показывает четко выраженную линейную зависимость или полное отсутствие взаимосвязи, то корреляция замечательно это отразит.
Но, если данные показывают нелинейную взаимосвязь (например, квадратичную), наличие отдельных групп значений или выбросов, то вычисленное значение коэффициента корреляции может ввести в заблуждение (см. файл примера).
Корреляция близкая к 1 или -1 (т.е. близкая по модулю к 1) показывает сильную линейную взаимосвязь переменных, значение близкое к 0 показывает отсутствие взаимосвязи. Положительная корреляция означает, что с ростом одного показателя другой в среднем увеличивается, а при отрицательной – уменьшается.Для вычисления коэффициента корреляции требуется, чтобы сопоставляемые переменные удовлетворяли следующим условиям:
- количество переменных должно быть равно двум;
- переменные должны быть количественными (например, частота, вес, цена). Вычисленное среднее значение этих переменных имеет понятный смысл: средняя цена или средний вес пациента. В отличие от количественных, качественные (номинальные) переменные принимают значения лишь из конечного набора категорий (например, пол или группа крови). Этим значениям условно сопоставлены числовые значения (например, женский пол – 1, а мужской – 2). Понятно, что в этом случае вычисление среднего значения, которое требуется для нахождения корреляции, некорректно, а значит некорректно и вычисление самой корреляции;
- переменные должны быть случайными величинами и иметь нормальное распределение.
Двумерные данные могут иметь различную структуру. Для работы с некоторыми из них требуются определенные подходы:
- Для данных с нелинейной связью корреляцию нужно использовать с осторожностью. Для некоторых задач бывает полезно преобразовать одну или обе переменных так, чтобы получить линейную взаимосвязь (для этого требуется сделать предположение о виде нелинейной связи, чтобы предложить нужный тип преобразования).
- С помощью диаграммы рассеяния у некоторых данных можно наблюдать неравную вариацию (разброс). Проблема неодинаковой вариации состоит в том, что места с высокой вариацией не только предоставляют наименее точную информацию, но и оказывают наибольшее влияние при расчете статистических показателей. Эту проблему также часто решают с помощью преобразования данных, например, с помощью логарифмирования.
- У некоторых данных можно наблюдать разделение на группы (clustering), что может свидетельствовать о необходимости разделения совокупности на части.
- Выброс (резко отклоняющееся значение) может исказить вычисленное значение коэффициента корреляции. Выброс может быть причиной случайности, ошибки при сборе данных или могут действительно отражать некую особенность взаимосвязи. Так как выброс сильно отклоняется от среднего значения, то он вносит большой вклад при расчете показателя. Часто расчет статистических показателей производят с и без учета выбросов.
Использование MS EXCEL для расчета корреляции
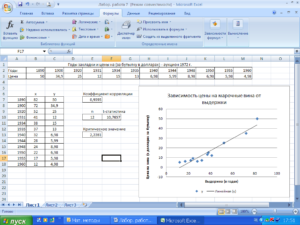
В качестве примера возьмем 2 переменные Х и Y и, соответственно, выборку состоящую из нескольких пар значений (Хi; Yi). Для наглядности построим диаграмму рассеяния.
Примечание: Подробнее о построении диаграмм см. статью Основы построения диаграмм. В файле примера для построения диаграммы рассеяния использована диаграмма График, т.к.
мы здесь отступили от требования случайности переменной Х (это упрощает генерацию различных типов взаимосвязей: построение трендов и заданный разброс).
В случае реальных данных необходимо использовать диаграмму типа Точечная (см. ниже).
Расчеты корреляции проведем для различных случаев взаимосвязи между переменными: линейной, квадратичной и при отсутствии связи.
Примечание: В файле примера можно задать параметры линейного тренда (наклон, пересечение с осью Y) и степень разброса относительно этой линии тренда. Также можно настроить параметры квадратичной зависимости.
В файле примера для построения диаграммы рассеяния в случае отсутствия зависимости переменных использована диаграмма типа Точечная. В этом случае точки на диаграмме располагаются в виде облака.
Примечание: Обратите внимание, что изменяя масштаб диаграммы по вертикальной или горизонтальной оси, облаку точек можно придать вид вертикальной или горизонтальной линии. Понятно, что при этом переменные останутся независимыми.
Как было сказано выше, для расчета коэффициента корреляции в MS EXCEL существует функций КОРРЕЛ(). Также можно воспользоваться аналогичной функцией PEARSON(), которая возвращает тот же результат.
Для того, чтобы удостовериться, что вычисления корреляции производятся функцией КОРРЕЛ() по вышеуказанным формулам, в файле примера приведено вычисление корреляции с помощью более подробных формул:
=КОВАРИАЦИЯ.Г(B28:B88;D28:D88)/СТАНДОТКЛОН.Г(B28:B88)/СТАНДОТКЛОН.Г(D28:D88)
=КОВАРИАЦИЯ.В(B28:B88;D28:D88)/СТАНДОТКЛОН.В(B28:B88)/СТАНДОТКЛОН.В(D28:D88)
Примечание: Квадрат коэффициента корреляции r равен коэффициенту детерминации R2, который вычисляется при построении линии регрессии с помощью функции КВПИРСОН().Значение R2 также можно вывести на диаграмме рассеяния, построив линейный тренд с помощью стандартного функционала MS EXCEL (выделите диаграмму, выберите вкладку Макет, затем в группе Анализ нажмите кнопку Линия тренда и выберите Линейное приближение). Подробнее о построении линии тренда см., например, в статье о методе наименьших квадратов.
Использование MS EXCEL для расчета ковариации
Ковариация близка по смыслу с дисперсией (также является мерой разброса) с тем отличием, что она определена для 2-х переменных, а дисперсия — для одной. Поэтому, cov(x;x)=VAR(x).
Для вычисления ковариации в MS EXCEL (начиная с версии 2010 года) используются функции КОВАРИАЦИЯ.Г() и КОВАРИАЦИЯ.В(). В первом случае формула для вычисления аналогична вышеуказанной (окончание .Г обозначает Генеральная совокупность), во втором – вместо множителя 1/n используется 1/(n-1), т.е. окончание .В обозначает Выборка.
Примечание: Функция КОВАР(), которая присутствует в MS EXCEL более ранних версий, аналогична функции КОВАРИАЦИЯ.Г().
Примечание: Функции КОРРЕЛ() и КОВАР() в английской версии представлены как CORREL и COVAR. Функции КОВАРИАЦИЯ.Г() и КОВАРИАЦИЯ.В() как COVARIANCE.P и COVARIANCE.S.
Дополнительные формулы для расчета ковариации:
=СУММПРОИЗВ(B28:B88-СРЗНАЧ(B28:B88);(D28:D88-СРЗНАЧ(D28:D88)))/СЧЁТ(D28:D88)
=СУММПРОИЗВ(B28:B88-СРЗНАЧ(B28:B88);(D28:D88))/СЧЁТ(D28:D88)
=СУММПРОИЗВ(B28:B88;D28:D88)/СЧЁТ(D28:D88)-СРЗНАЧ(B28:B88)*СРЗНАЧ(D28:D88)
Эти формулы используют свойство ковариации:
Если переменные x и y независимые, то их ковариация равна 0. Если переменные не являются независимыми, то дисперсия их суммы равна:
VAR(x+y)= VAR(x)+ VAR(y)+2COV(x;y)
А дисперсия их разности равна
VAR(x-y)= VAR(x)+ VAR(y)-2COV(x;y)
Оценка статистической значимости коэффициента корреляции
При проверке значимости коэффициента корреляции нулевая гипотеза состоит в том, что коэффициент корреляции равен нулю, альтернативная — не равен нулю (про проверку гипотез см. статью Проверка гипотез).
Для того чтобы проверить гипотезу, мы должны знать распределение случайной величины, т.е. коэффициента корреляции r. Обычно, проверку гипотезы осуществляют не для r, а для случайной величины tr:
которая имеет распределение Стьюдента с n-2 степенями свободы.
Если вычисленное значение случайной величины |tr| больше, чем критическое значение tα,n-2 (α- заданный уровень значимости), то нулевую гипотезу отклоняют (взаимосвязь величин является статистически значимой).
Коэффициент корреляции в Excel: что это, как рассчитать? Формула, пример, анализ данных онлайн
Различные признаки могут быть связаны между собой.
Выделяют 2 вида связи между ними:
- функциональная;
- корреляционная.
Корреляция в переводе на русский язык – не что иное, как связь.
В случае корреляционной связи прослеживается соответствие нескольких значений одного признака нескольким значениям другого признака. В качестве примеров можно рассмотреть установленные корреляционные связи между:
- длиной лап, шеи, клюва у таких птиц как цапли, журавли, аисты;
- показателями температуры тела и частоты сердечных сокращений.
Для большинства медико-биологических процессов статистически доказано присутствие этого типа связи.
Статистические методы позволяют установить факт существования взаимозависимости признаков. Использование для этого специальных расчетов приводит к установлению коэффициентов корреляции (меры связанности).
Такие расчеты получили название корреляционного анализа. Он проводится для подтверждения зависимости друг от друга 2-х переменных (случайных величин), которая выражается коэффициентом корреляции.
Использование корреляционного метода позволяет решить несколько задач:
- выявить наличие взаимосвязи между анализируемыми параметрами;
- знание о наличии корреляционной связи позволяет решать проблемы прогнозирования. Так, существует реальная возможность предсказывать поведение параметра на основе анализа поведения другого коррелирующего параметра;
- проведение классификации на основе подбора независимых друг от друга признаков.
Для переменных величин:
- относящихся к порядковой шкале, рассчитывается коэффициент Спирмена;
- относящихся к интервальной шкале – коэффициент Пирсона.
Это наиболее часто используемые параметры, кроме них есть и другие.
Значение коэффициента может выражаться как положительным, так и отрицательными.
В первом случае при увеличении значения одной переменной наблюдается увеличение второй. При отрицательном коэффициенте – закономерность обратная.
Для чего нужен коэффициент корреляции?
Данный статистический показатель позволяет не только проверить предположение о существовании линейной взаимосвязи между признаками, но и установить ее силу.
Случайные величины, связанные между собой, могут иметь совершенно разную природу этой связи.
Не обязательно она будет функциональной, случай, когда прослеживается прямая зависимость между величинами.
Чаще всего на обе величины действует целая совокупность разнообразных факторов, в случаях, когда они являются общими для обеих величин, наблюдается формирование связанных закономерностей.
Это значит, что доказанный статистически факт наличия связи между величинами не является подтверждением того, что установлена причина наблюдаемых изменений. Как правило, исследователь делает вывод о наличии двух взаимосвязанных следствий.
Свойства коэффициента корреляции
Этой статистической характеристике присущи следующие свойства:
- значение коэффициента располагается в диапазоне от -1 до +1. Чем ближе к крайним значениям, тем сильнее положительная либо отрицательная связь между линейными параметрами. В случае нулевого значения речь идет об отсутствии корреляции между признаками;
- положительное значение коэффициента свидетельствует о том, что в случае увеличения значения одного признака наблюдается увеличение второго (положительная корреляция);
- отрицательное значение – в случае увеличения значения одного признака наблюдается уменьшение второго (отрицательная корреляция);
- приближение значения показателя к крайним точкам (либо -1, либо +1) свидетельствует о наличии очень сильной линейной связи;
- показатели признака могут изменяться при неизменном значении коэффициента;
- корреляционный коэффициент является безразмерной величиной;
- наличие корреляционной связи не является обязательным подтверждением причинно-следственной связи.
Значения коэффициента корреляции
Охарактеризовать силу корреляционной связи можно прибегнув к шкале Челдока, в которой определенному числовому значению соответствует качественная характеристика.
В случае положительной корреляции при значении:
- 0-0,3 – корреляционная связь очень слабая;
- 0,3-0,5 – слабая;
- 0,5-0,7 – средней силы;
- 0,7-0,9 – высокая;
- 0,9-1 – очень высокая сила корреляции.
Шкала может использоваться и для отрицательной корреляции. В этом случае качественные характеристики заменяются на противоположные.
Можно воспользоваться упрощенной шкалой Челдока, в которой выделяется всего 3 градации силы корреляционной связи:
- очень сильная – показатели ±0,7 — ±1;
- средняя – показатели ±0,3 — ±0,699;
- очень слабая – показатели 0 — ±0,299.
Данный статистический показатель позволяет не только проверить предположение о существовании линейной взаимосвязи между признаками, но и установить ее силу.
Виды коэффициента корреляции
Коэффициенты корреляции можно классифицировать по знаку и значению:
- положительный;
- нулевой;
- отрицательный.
В зависимости от анализируемых значений рассчитывается коэффициент:
- Пирсона;
- Спирмена;
- Кендала;
- знаков Фехнера;
- конкорддации или множественной ранговой корреляции.
Корреляционный коэффициент Пирсона используется для установления прямых связей между абсолютными значениями переменных. При этом распределения обоих рядов переменных должны приближаться к нормальному. Сравниваемые переменные должны отличаться одинаковым числом варьирующих признаков. Шкала, представляющая переменные, должна быть интервальной либо шкалой отношений.
Метод Пирсона рекомендуется использовать для ситуаций, требующих:
- точного установления корреляционной силы;
- сравнения количественных признаков.
Недостатков использования линейного корреляционного коэффициента Пирсона немного:
- метод неустойчив в случае выбросов числовых значений;
- с помощью этого метода возможно определение корреляционной силы только для линейной взаимосвязи, при других видах взаимных связей переменных следует использовать методы регрессионного анализа.
Ранговая корреляция определяется методом Спирмена, позволяющим статистически изучить связь между явлениями. Благодаря этому коэффициенту вычисляется фактически существующая степень параллелизма двух количественно выраженных рядов признаков, а также оценивается теснота, выявленной связи.
Метод Спирмена рекомендуется применять в ситуациях:
- не требующих точного определения значение корреляционной силы;
- сравниваемые показатели имеют как количественные, так и атрибутивные значения;
- равнения рядов признаков с открытыми вариантами значений.
Метод Спирмена относится к методам непараметрического анализа, поэтому нет необходимости проверять нормальность распределения признака. К тому же он позволяет сравнивать показатели, выраженные в разных шкалах. Например, сравнение значений количества эритроцитов в определенном объеме крови (непрерывная шкала) и экспертной оценки, выражаемой в баллах (порядковая шкала).
На эффективность метода отрицательно влияет большая разница между значениями, сравниваемых величин. Не эффективен метод и в случаях когда измеряемая величина характеризуется неравномерным распределением значений.
Пошаговый расчет коэффициента корреляции в Excel
Расчёт корреляционного коэффициента предполагает последовательное выполнение ряда математических операций.
Приведенная выше формула расчета коэффициента Пирсона, показывает насколько трудоемок этот процесс если выполнять его вручную.
Использование возможностей Excell ускоряет процесс нахождения коэффициента в разы.
Достаточно соблюсти несложный алгоритм действий:
- введение базовой информации – столбец значений х и столбец значений у;
- в инструментах выбирается и открывается вкладка «Формулы»;
- в открывшейся вкладке выбирается «Вставка функции fx»;
- в открывшемся диалоговом окне выбирается статистическая функция «Коррел», позволяющая выполнить расчет корреляционного коэффициента между 2 массивами данных;
- открывшееся окно вносятся данные: массив 1 – диапазон значений столбца х (данные необходимо выделить), массив 2 – диапазон значений столбца у;
- нажимается клавиша «ок», в строке «значение» появляется результат расчета коэффициента;
- вывод относительно наличия корреляционной связи между 2 массивами данных и ее силе.
Загрузка…